OpenAI is making it easier to generate realistic photos

OpenAI on Tuesday announced that the company is integrating its latest image-generation technology into its chatbot, ChatGPT, using the GPT-40 model the company unveiled last year.
With the combined technology, ChatGPT could become a one-stop shop for artificially generated content, replacing Dall-E 3, a separate system just for image creation.
Instead of Dall-E 3, ChatGPT’s image generation will instead use Sora, a separate platform the company unveiled last year that is dedicated to video generation. OpenAI didn’t detail any plans for video-generation capabilities using ChatGPT in its press release.
OpenAI said the biggest advancement in the chatbot’s image ability is in the quality of its text rendering abilities. The company claims its systems can now generate images with text that is meaningful and readable — not warped and typo-ridden.
“We trained our models on the joint distribution of online images and text, learning not just how images relate to language, but how they relate to each other,” the company said in a press release. “Combined with aggressive post-training, the resulting model has surprising visual fluency, capable of generating images that are useful, consistent, and context-aware.”
The company said this system will be able to use user-uploaded images as visual inspirations and is better at following instructions. OpenAI claims that “while other systems struggle with ~5-8 objects, GPT‑4o can handle up to 10-20 different objects.”
The advancements come with some trade-offs, however: The model might crop longer images near the bottom, is still prone to seeing things that aren’t there, and struggles to render non-Latin languages or images that contain text at a very small size.
GPT-4o is available immediately on ChatGPT’s plus, pro, team, and free subscription tiers, but “plus” subscribers have higher usage limits than “free” subscribers. The company said the feature will roll out soon for enterprise and edu users, as well as for developers using the API.
Here are some of the image demonstrations from the company’s press release.
Detailed images

For this picture, the prompt was as follows:
A wide image taken with a phone of a glass whiteboard, in a room overlooking the Bay Bridge. The field of view shows a woman writing, sporting a tshirt wiith a large OpenAI logo. The handwriting looks natural and a bit messy, and we see the photographer’s reflection.
Magnetic poetry

For this picture, the prompt was as follows:
magnetic poetry on a fridge in a mid century home:
Line 1: “A picture”
Line 2: “is worth”
Line 3: “a thousand words,”
Line 4: “but sometimes”Large gapLine 5: “in the right place”
Line 6: “can elevate”
Line 7: “its meaning.
“The man is holding the words “a few” in his right hand and “words” in his left.
Comic strips

For this picture, the prompt was as follows:
Make an image of a four‑panel strip, with some padding around the border:
A little snail is at the counter of a flashy car showroom. The salesman has leaned way over the desk to even see him.
Close‑up on the snail looking very serious. He says, “I want your fastest sports car… and I want you to paint big letter ‘S’s on the doors, the hood and the roof.”
The salesman is scratching his head. “Um… we can do that, but why the S’s?”
Smash cut to a red blur roaring down the highway. The sports car is covered in giant S’s. People on the sidewalk are pointing and laughing: “WOW! LOOK AT THAT S‑CAR GO!”
Infographics on science experiments
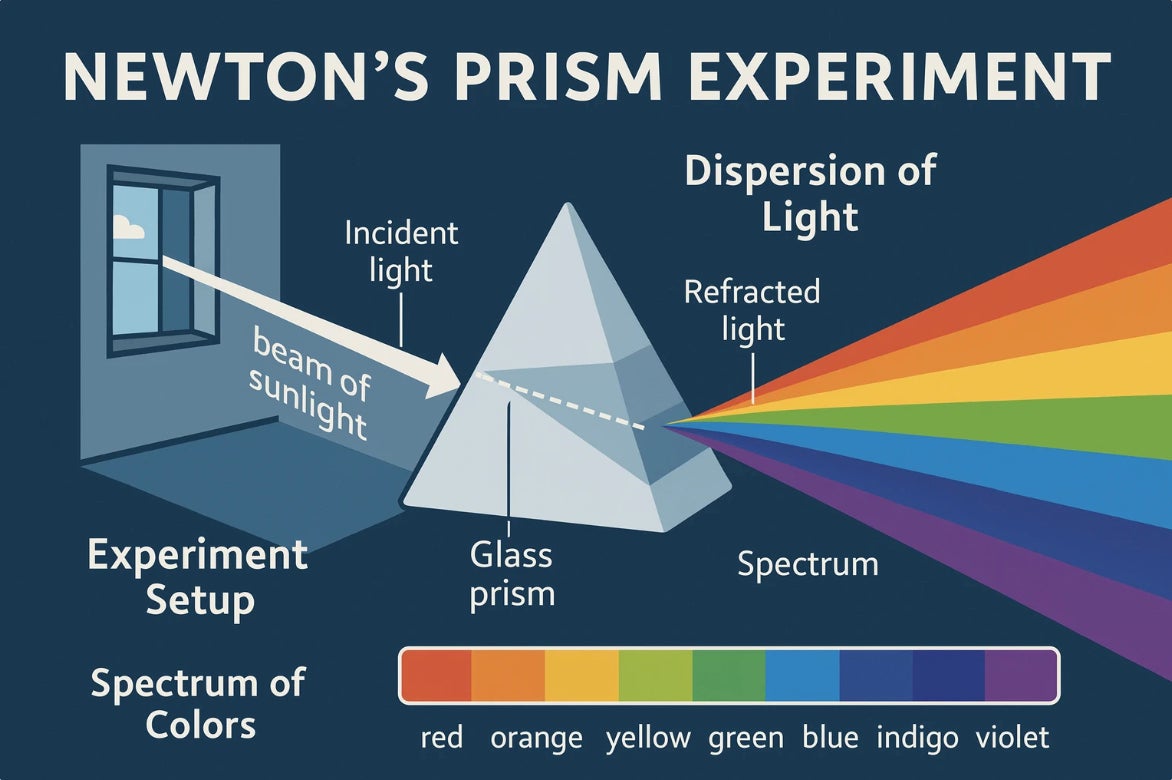
For this picture, the prompt was as follows:
an infographic explaining newton’s prism experiment in great detail.
...updated to look hand-drawn

...then, for this picture, the company asked the system to go a bit further, building on the previous image. The prompt was as follows:
now generate a POV of a person drawing this diagram in their notebook, at a round cafe table in washington square park
...and updated further

...and the developers went one last step from the previous image. The prompt was as follows:
now show the same scene with a smug young Isaac Newton sitting at the table, with a prism, demonstrating the experiment, without the notebook in view
Detailed street signs

For this picture, the prompt was as follows:
Create a photorealistic image of two witches in their 20s (one ash balayage, one with long wavy auburn hair) reading a street sign.
Context:
Artistic interpretations

For this picture, Eskcanta, a creator on Discord, asked ChatGPT to create an image based on the prompt as follows:
We need evidence there is a currently present invisible elephant. Consider what an elephant is and does in the environment, then show us that, perhaps mid-process - but the elephant itself is not shown at all
Cocktail recipes

For this picture, the prompt was as follows:
Make me a professionally shot photorealistic diagram of the top selling cocktails in my bar with recipes labeled on each drink.
put the recipes on handwritten cards in front of each drink.
the cards are brown, and the text is black.
background is white
Title is “4 most popular cocktails”
Realistic interpretations of wild imagination

For this picture, the prompt was as follows:
A candid paparazzi-style photo of Karl Marx hurriedly walking through the parking lot of the Mall of America, glancing over his shoulder with a startled expression as he tries to avoid being photographed. He’s clutching multiple glossy shopping bags filled with luxury goods. His coat flutters behind him in the wind, and one of the bags is swinging as if he’s mid-stride. Blurred background with cars and a glowing mall entrance to emphasize motion. Flash glare from the camera partially overexposes the image, giving it a chaotic, tabloid feel.